1. INTRODUCCIÓN
El sistema de Atención Primaria de Salud (APS) cumple un rol importante para la atención oportuna a usuarios de la red pública de salud, según Bass del Campo (2012), sin embargo, los pacientes del APS tienen un tiempo de demora alto no solo para programar una cita médica sino también el tiempo que transcurre para la atención (Bedregal y otros. 2009). Las personas que son parte de la APS deben esperar largas horas desde muy temprano para poder obtener una cita médica. La espera involucra que el paciente deja de percibir un ingreso debido a que dejan de trabajar todo su turno en algunos casos para obtener la cita médica, el traslado es otra variable que incide ejemplo de ello son los pacientes que se trasladan desde sus hogares hacia el establecimiento de salud tardan horas en realizar el recorrido, debido a las condiciones geográficas que presentan las zonas rurales (Jiménez, 2018).
Los tiempos de espera prolongados y las deficiencias de acceso a las instalaciones de salud impactan negativamente a los pacientes y eventualmente a sus acompañantes, quienes presentan altos niveles de estrés a causa del alto flujo de personas que demandan el servicio. (Pesse-Sorensen, Fuentes-García & Ilabaca, 2019). Un paciente de avanzada edad irá acompañado y el acompañante también deberá disponer de su tiempo, una madre con hijos, un paciente con enfermedades crónicas y una mujer embarazada posiblemente todos tendrán que disponer del día completo para poder obtener la cita y posteriormente ser atendidos (Ansell et al., 2017).
Los largos tiempos de espera están explicados por una serie de factores que influyen en la programación de citas médicas. Estos factores pueden ser la escasa disponibilidad, la hora en el que el paciente se levanta para lograr conseguir un número de atención, el turno del paciente en el que queda para que le asignen la hora médica y su posterior atención. Adicionalmente, factores externos como la limitada oferta de horas disponibles en las infraestructuras de salud pública (Brandenburg et al., 2015).
Además, existen pacientes que no asisten a sus citas dejando sin atención a pacientes que sí necesitan atención de manera urgente (Salazar et al., 2020). Todo ello ofrece evidencia de que existe un problema de gestión de asignación de citas latentes en los sistemas públicos de salud, lo que conlleva principalmente a costos en tiempos de espera y atención a la cita médica o no médica (Coloma y otros. 2020). La entrega de un servicio mejorado en la programación de citas y acceso de los pacientes ayuda a reducir el estrés, costos de atención y reavivar la satisfacción en la prestación del servicio de salud público.
La pregunta de investigación es si es posible optimizar el agendamiento de citas médicas de APS usando métodos de aprendizaje automático, reduciendo el impacto negativo en la población objetivo. A la fecha, no hay estudios que han tratado de crear una solución para esta problemática.
2. ANTECEDENTES TEÓRICOS
2.1. Sistemas de salud
Los sistemas de salud en el mundo son diferentes debido a la combinación de factores que son considerados para su establecimiento (Schütte, Acevedo & Flahault, 2018). Los factores que se miden son esencialmente la tasa de mortalidad y natalidad de la población, la fuerza laboral y la infraestructura hospitalaria que incluye las instalaciones, número de camas y acceso a la salud (Durrani, 2016). La expansión en la atención hospitalaria se ha desarrollado principalmente alrededor de centros urbanos o cercanos a estos lo que lleva a una distribución desigual de las instalaciones de salud, acceso a camas y atención primaria. Las variaciones en la asignación pública al servicio de salud a nivel global conllevan a la disminución en la calidad de los servicios y alcance de los recursos humanos de salud (Bloom, Khoury & Subbaraman, 2018).
La comparación de servicios de salud se puede dar por el tiempo de espera para ser atendidos, según Dixit & Sambasivan (2018), realizaron un estudio de los servicios de salud, en el encontraron que en Australia 10% de los pacientes tiene que esperar hasta cuatro meses para cirugías electivas, mientras que en Canadá solo un 4% de los pacientes deben esperar. Así mismo, solo 7% de los pacientes en Francia han experimentados problemas de coordinación o programación de servicios de salud y en Estados Unidos los pacientes experimentan un problema con las altas médicas en un 28%. Uno de los sistemas de salud más costoso y de peor desempeño es el estadounidense a pesar de ser uno de los países más industrializados (Ahluwalia et al., 2017). Lo que implica que no necesariamente un buen servicio de salud está relacionado con el desarrollo del país. Debido a las limitaciones de capacidad, algunos pacientes deben ser agregados a listas de espera, para recibir tratamientos o ser atendidos. Esto trae implicaciones para los pacientes como son 1) largas listas de espera, 2) algunos pacientes no pueden esperar su turno para ser atendidos y recurren al sistema privado, 3) el costo administrativo de las listas y 4) las listas de espera ponen en desuso las camas que están disponibles. Estas listas no incluyen el acceso a servicio de citas médicas que es otro problema de los servicios de salud. Muchos de los esfuerzos están enfocados en el servicio de atención primaria con la inclusión de sistemas de información de alto desempeño.
El sistema de salud chileno es un sistema mixto que consta de dos sectores; público y privado (Almeida, Oliveira & Giovanella, 2018). El sector público cubre al 80% de la población en su mayoría a través del Fondo Nacional de Salud (FONASA) por medio del Sistema Nacional de Servicios de Salud (SNSS) y la red de Servicios de Salud Regional y el Sistema Municipal de Atención Primaria. Este incluye las atenciones primarias y hospitalarias. El sector privado está constituido por las instituciones de Salud Previsional (ISAPRES), que proveen servicios a través de instalaciones privadas como públicas (Almeida, Oliveira & Giovanella, 2018).
En un esfuerzo por establecer un sistema de información que permitiera impulsar una estrategia y un plan de acción para digitalizar los establecimientos que conforman la red asistencial de salud de Chile se estableció a través de la Subsecretaria de Redes Asistenciales creo en el 2008 el Sistema de Información de la Red Asistencial (SIDRA). (Reynaldos-Grandón, Saiz-Alvarez & Molina-Muñoz, 2018). Inicialmente permitió apoyar los procesos básicos de informatización, dando prioridad a la Agenda, referencia y control de referencia, registro de población de control, dispensación de fármacos y urgencia. Los cuales se encuentran incorporados en diferentes grados de implementación y alcance de componentes en distintos establecimientos de salud de la red local.
2.2 Tiempos de espera y programación de citas de pacientes
El tiempo de acceso a citas en la atención primaria genera gastos emocionales, psicológicos que pueden agravar condiciones preexistentes en la población, así como costos económicos del sistema médico por costos de coordinación de personal y tiempos de atención. (Ansell et al., 2017). Del mismo modo, las citas médicas que no son atendidas bien sean por la inasistencia de los pacientes, médicos o por otras razones generan pérdida de recursos, desorganización de los servicios entre otros problemas (Salazar et al. 2020).
Los tiempos de espera para atención médica en servicios de salud público chileno, en especial los consultorios periféricos suelen ser prolongados. Los pacientes deben asistir con horas de antelación para ser atendidos o esperar en listas de esperas por algunos servicios (Almeida, Oliveira & Giovanella, 2018). El sistema de salud pública y su enfoque actual presenta inequidad e ineficiencia en cuanto a la atención y asignación de citas (Annick , 2002). Ninguna otra institución trabaja tan contra reloj como el servicio de salud. Sin embargo, la falta de personal y cambios en turnos de trabajo hace que el personal esté insatisfecho y por consiguiente influye en la satisfacción de los pacientes (Abdalkareem et al., 2021). El incremento de la expectativa de vida de la población lleva un incremento en la demanda de servicios médicos (Rais & Viana, 2011). Por tanto, se requiere la mejora en la asignación de recursos y personal en los servicios médicos, como un sistema de citas.
Un sistema de citas efectivo debe abarcar la demanda basado en la capacidad de asignación de recursos de manera eficiente y que disminuya el tiempo de espera de los pacientes, mejorar el acceso a los servicios médicos y tener un impacto en la calidad de las operaciones en los servicios de salud (Abdalkareem et al., 2021). Mejorar la eficiencia en el sistema de salud tiene el potencial no solo de disminuir costos sino facilitar el acceso igualitario a la salud (Batun & Begen, 2013). La atención de pacientes en centro de atención primaria de salud (APS) puede mejorar la flexibilidad en la asignación de citas disminuyendo los cuellos de botella en asignación de recursos y disponibilidad de profesionales (Murray & Berwick, 2003). Adicionalmente, un acceso avanzado a la salud reduce los tiempos de espera, restricciones a ciertos días de la semana y horarios diarios. Si bien puede parecer que se crean días con múltiples asignaciones, la variación natural de la demanda y el perfilar los pacientes en realidad distribuye de manera uniforme todo el calendario de citas.
2.3 Máquinas de aprendizaje para horarios de atención en servicios médicos
Las máquinas de aprendizaje (ML) son algoritmos que permiten aprender los patrones en una serie de datos sin que se programen explícitamente. Existen algoritmo de ML supervisados y no supervisados (Syam & Sharma, 2018). Los supervisados son generalmente un conjunto de herramientas para clasificar y procesar datos que están etiquetados. Los no supervisados permiten organizar en grupos basados en características particulares entre ellos.
Algunos algoritmos ML usados para clasificación son: Árboles de decisión, es un método que permite generar reglas para clasificar los datos basado en una representación con una estructura de árbol (Jahromi, Stakhovych & Ewing, 2014). Bosques aleatorios que es un algoritmo que usa múltiples árboles de decisión, o estructuras de datos estadísticos y selecciona la mejor división de etiquetado durante entrenamiento y luego promedia para crear la predicción más balanceada (Salminen et al., 2019). K-vecinos más cercanos, es un método no paramétrico de clasificación. Requiere especificar la una función de similitud que produce valores de similitud entre pares que responden a una variable de interés y el número de vecinos cercanos (Arora et al., 2019; Dzyabura, Jagabathula & Muller, 2019). Naive Bayes está basado en el teorema de Bayes. El algoritmo asigna etiquetas de clases a las instancias problema que son representadas como vectores de valores de entidad donde las etiquetas de clase se extraen de algún conjunto finito (Sánchez-Franco et al., 2019). Las máquinas de soporte vectorial son métodos de clasificación que emplean el mapeo de un vector de entrada en un espacio hiper-dimensional de características, construyendo un modelo lineal que implementa clases no lineales en el espacio original (Kim, 2021).
Recientemente, las máquinas de aprendizaje han ganado importancia en servicios de atención médica, dado su habilidad para mejorar el rendimiento del sistema de salud (Pianykh et al., 2020). Algunas aplicaciones de aprendizaje automático, tratan de predecir pacientes que no asistirán a sus citas médicas (Srinivas & Ravindran, 2018). En este trabajo se evalúan cinco algoritmos de clasificación, regresión logística, redes neuronales artificiales, Bosques aleatorios a los algoritmos ensamblados como son Gradient Boosting y Stacking (Srinivas & Ravindran, 2018). Otra aplicación usando ML pretende medir el tiempo del postoperatorio de los pacientes, basado en el tiempo de recuperación individual del paciente (Kempa-Liehr et al., 2020). La predicción de los tiempos de espera y retrasos en la asignación de citas médicas se han estudiado usando aprendizaje automático (Curtis et al., 2018). En este trabajo se compararon diferentes algoritmos como redes neuronales, bosques aleatorios, máquinas de soporte vectorial, redes elásticas, k-vecinos más cercanos entre otros. El resultado mostró que las redes elásticas generan el mejor desempeño y logran identificar el predictor más importante. Otro problema que se ha resuelto usando aprendizaje automático tiene relación con la inasistencia a las citas y el perfil de pacientes que no se presentan Salazar et al. (2020) o citas otorgadas en exceso o ignoradas Samorani et al. (2022) enfocándose en un modelo de asignación de citas que sea equitativo para todos.
3. MATERIALES Y MÉTODOS
3.1. Datos de estudio
Se realizó la recolección y representación de datos con un diseño de estudio cuantitativo descriptivo transversal. El grupo objetivo fueron usuarios mayores de 18 años del sistema público y privado de Chile. Se obtuvieron datos de 238 personas residentes de zonas urbanas y rurales en 15 regiones, con un marco conceptual de 203 ciudades del país. La recolección de datos se realizó a través de una encuesta de opinión en línea y el instrumento a utilizar fue un cuestionario estructurado compuesto principalmente por preguntas cerradas, de carácter simple y múltiple y otra parte, con cuestionarios no estructurados los cuales tuvieron como principal objetivo obtener una opinión acerca de la expectativa de los usuarios del sistema mixto de salud de Chile. La difusión fue por redes sociales y grupos de aplicaciones web.
3.2. Análisis de los datos obtenidos
Los datos obtenidos de la encuesta según la situación laboral presentan es mostrada en la Tabla 1, donde cerca del 60% de las personas trabajan tiempo completo o trabajan por cuenta propia (mipymes o negocio familiar), cerca de un 10% son dueño(a) de casa, solo un 5% trabaja tiempo parcial, y un porcentaje de estudiantes que alcanza no alcanza el 20% (en su mayoría universitarios).
La Figura 1 muestra la distribución de edades de los encuestados. La mayoría de las personas que respondieron se encuentran entre los 30 y 50 años, seguido de personas entre 20 y 30 años y en menos cantidad personas mayores a 50 años. Los segmentos con más representación corresponden a la edad productiva por lo que coincide con la situación laboral obtenida. La mayoría de las personas que respondieron la encuesta son mujeres que representan un 70.64% del total obtenido, por otro lado, los hombres representan un 29,36%.
Se revisó el nivel de ingreso de las personas (Fig. 2), en su mayoría no superaron los $200.000. Si bien es posible que exista sesgo en los datos entregados por las personas, aproximadamente un 30% de las personas respondieron que esa era la opción que mejor representa sus ingresos. Por otro lado, un 21% de las personas señalaron tener ingresos sobre los $1.200.000, y el restante en un rango entre 200.000 y 1.000.000 (Clase media).
Tabla 1. Situación
laboral presente en los datos recolectados
|
Situación laboral |
Porcentaje |
N |
|
Estudiante |
17 |
40 |
|
Trabajo de tiempo completo |
49 |
116 |
|
Trabajo a tiempo parcial |
5 |
11 |
|
Trabaja por cuenta propia |
11 |
25 |
|
Sin trabajo, pero en búsqueda |
6 |
15 |
|
Sin trabajo y no busca |
2 |
5 |
|
Jubilado por edad legal |
0.1 |
1 |
|
Jubilado por motivos de salud |
1 |
2 |
|
Dueño(a) de casa |
10 |
23 |
Fuente: los autores

Figura 1. Distribución de edades
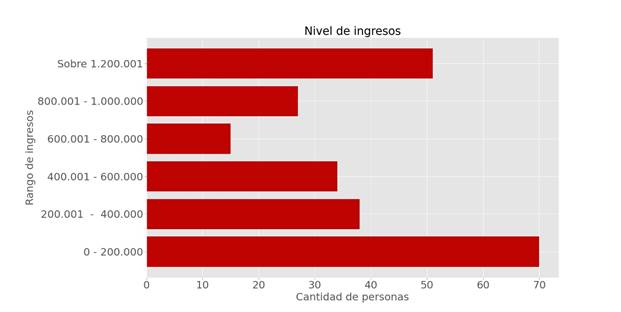
Figura 2. Distribución de nivel de ingresos
Una característica importante que se obtuvo de los datos recopilados es la cantidad de personas que si bien no necesitan ayuda para dirigirse a los centros médicos (7,23%) donde asisten regularmente, si hay un gran porcentaje de personas que deben acompañar a pacientes (76,17%) para dirigirse hacia el centro de salud al que asisten.
La Figura 3 muestra las preferencias de horarios para citas médicas, según rangos de edad. Independiente del rango de edad la preferencia es el “Horario A” de 08:30 a 10:00 horas, seguido del “Horario D” de 16:00 a 18:00 horas, y un pequeño porcentaje que se encuentra en el “Horario F” que representa a las personas sin ninguna preferencia en particular. Igualmente, se buscó si había diferencia en la preferencia horaria en personas que padecían alguna enfermedad crónica, tenían hijos o por frecuencia de asistencia al servicio de salud. Sin embargo, las preferencias seguían siendo las mismas.
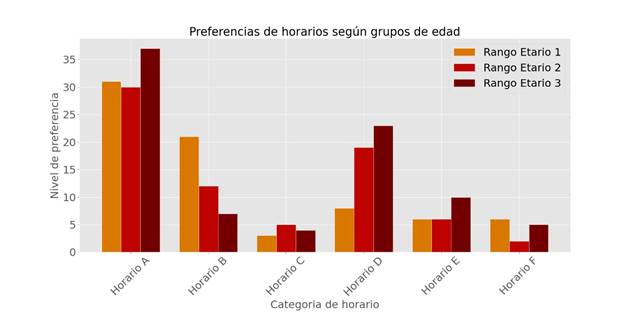
Figura 3. Distribución de horarios por categorías y rango etario
Otro aspecto que se consideró en los datos es el tipo de previsión que poseen los usuarios. La Tabla 2 muestra que la mayoría de las personas que respondieron la encuesta se atienden en centros de atención de salud pública, en donde no existen sistemas de toma de citas de médica automático, sino que cada usuario debe asistir al centro para tomar cita y ser atendido.
Tabla 2. Tipo de Previsión de salud por estrato
|
Previsión |
Porcentaje |
N |
|
Fonasa (A o B) |
41 |
101 |
|
Fonasa (C o D) |
33 |
80 |
|
Isapre |
22 |
55 |
|
Prais, Dipreca, Caprdena |
3 |
8 |
|
Otros |
1 |
2 |
Fuente: los autores
4. RESULTADOS Y DISCUSIÓN
4.1. Máquinas de aprendizaje usadas para asignación de horas
Se usaron algoritmos de clasificación para asignar el horario de las citas de acuerdo con las características presentadas por cada usuario. Como datos de entrada se tienen todas las características que se lograron obtener de los usuarios. Y la salida es la clasificación de horarios compuesta de seis bloques horarios, A, B, C son horarios matutinos mientras que D, E, F son horarios vespertinos.
Árbol de Decisión
La Tabla 3 muestra que para el algoritmo de árbol de decisión la precisión más alta se obtuvo desde una profundidad inicial igual a 7, con una precisión del 48,6% utilizando el criterio de Gini y un porcentaje del 30% de los datos para entrenamiento del algoritmo.
Con los datos obtenidos se realizó una medición de manera independiente para los parámetros correspondientes. Bajo este caso se obtuvo una presión de 38,3% y una validación cruzada igual a 40% de presión con una desviación estándar de 0.07.
Tabla 3. Resultados algoritmo: Árbol de decisión
|
Nivel de profundidad |
Precisión (%) |
|
1 |
48.6122 |
|
2 |
39.7959 |
|
3 |
39.3878 |
|
4 |
39.7959 |
|
5 |
48.6122 |
|
6 |
41.0204 |
|
7 |
48.6122 |
|
19 |
48.6122 |
Fuente: los autores
El algoritmo presenta una precisión promedio cercana al 50%, debido a la asertividad que se obtiene en la clase B (segundo horario preferente) sobre las demás clases en la matriz de confusión. Dicha matriz presenta los aciertos que obtuvo el algoritmo luego del entrenamiento, siendo la clase B la que registró casi el 90% de los aciertos en comparación con las demás clases presentes para la variable objetivo.
En la Figura 4 se pueden ver los resultados del entrenamiento del algoritmo en la clasificación. Si la previsión es menor o igual a 1.5 y es verdadero pertenece a la clase=b, si es falso realizó otra pregunta; si el nivel de ingreso es menor igual a 4.5 entonces se generó otro nodo y se debió preguntar; si el nivel de ingreso es menor o igual a 1.5 y así sucesivamente.
K-Vecinos más Cercanos
En los resultados obtenidos para las pruebas con este algoritmo se utilizaron diferentes formas para la métrica, en cuanto a la distancia entre los puntos y la cantidad de vecinos para cada tipo de métricas.
En el Tabla 4 se muestra el resumen de las pruebas para el algoritmo utilizando la métrica de Minkowsky, cantidad de vecinos desde 1 a 19, P = 2 y Weights = distance. La tabla 4, es un resumen de los datos originales obtenidos.
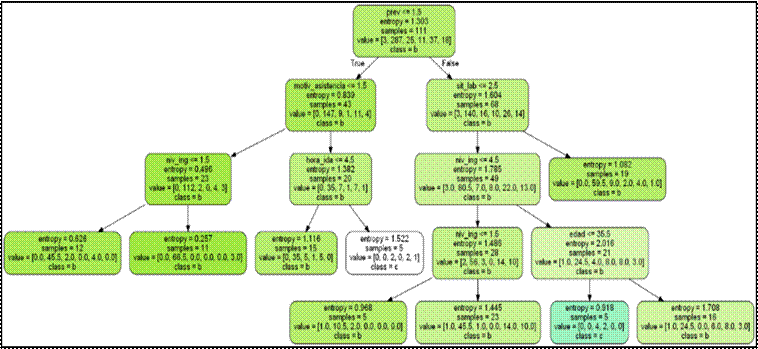
Figura 4. Resultado del árbol de decisión para predecir el horario de asignación de cita
Para esta configuración de parámetros se obtiene una precisión mínima de 0.2942 con una cantidad de vecinos igual a 1 y una precisión máxima de 0.4092 con una cantidad de vecinos igual a 19.
Tabla 4. Resultados algoritmo: Árbol de decisión
|
K= |
Precisión (%) |
|
1 |
29.4384 |
|
… |
… |
|
12 |
39.2029 |
|
13 |
37.9348 |
|
14 |
37.5181 |
|
15 |
40.0 |
|
16 |
40.0725 |
|
17 |
39.2391 |
|
18 |
40.0543 |
|
19 |
40.9239 |
Fuente: los autores
Para la creación del algoritmo final se seleccionan los parámetros que entregan una mayor precisión. En este caso el último registro de parámetros. La precisión del algoritmo final es de 42,5% con una validación cruzada igual a 40% y una desviación estándar de 0.05. Posterior a ello se realizó el reporte de clasificación donde se obtuvieron precisiones bastante altas para las clases B, C y E, de igual manera que el valor de recall o la sensibilidad para esas clases fueron mayores respecto a los otros algoritmos analizados, donde la clase B tuvo un asertividad del 89%, luego C y E con un 20% para cada clase.

Figura 5. Resultado del algoritmo K-Vecinos más cercanos para predecir el horario de asignación de cita
La Figura 5 muestra el límite de decisión para el algoritmo de K-Vecinos más Cercanos con los parámetros seleccionados en un principio, donde la clase B se representa con la forma 1 (triángulo), la clase C con la forma 2(circulo verde) y la clase E se representa con la forma 4 (triángulo invertido). En esta figura se puede ver que las tres clases (B, C y E) mencionadas anteriormente son prácticamente las únicas que se pueden visualizar.
Las demás clases no se visualizan en la figura del límite de decisión debido a que, al tener menor cantidad de registros en la base de datos utilizada, es posible que estas quedaran fuera del conjunto de datos utilizados para entrenar el algoritmo y debido a esto las predicciones para estas clases faltantes (A, D y F) no fueron precisas.
Máquinas de Soporte Vectorial
En este algoritmo se obtuvieron resultados similares para diferentes grupos de parámetros. Como se muestra en el cuadro V, se configuraron tanto el valor de kernel, y C. Este cuadro es un resumen de los datos originales obtenidos. Para los kernels de tipo lineal, gaussiano y polinomial, además de un valor de C desde 0.05 hasta 1.00 se obtuvo una precisión promedio de 41,8% en cada conjunto de parámetro, en cambio para un kernel de tipo sigmoide y manteniendo los mismos valores para C, se obtuvieron diferentes niveles de precisión para los algoritmos, con un promedio final de 36,6%.
Tabla 5. Resultados algoritmo Máquinas de Soporte Vectorial
|
Kernel |
C |
Precisión media (%) |
|
Linear |
0.05 a 1.00 |
41.85 |
|
Poly |
0.05 a 1.00 |
41.85 |
|
RBF |
0.05 a 1.00 |
41.85 |
|
Sigmoide |
0.05 a 1.00 |
36.57 |
Fuente: los autores
Aun así, se seleccionaron los parámetros que entregan una mejor precisión para la creación del algoritmo final para realizar una gráfica del límite de decisión para cada una de las clases de salida del algoritmo. Esto se puede observar en la Fig. 6, donde se muestra el límite de la región de decisión de cada clase. Aquí se puede observar que al igual que el algoritmo K-Vecinos más Cercanos, las categorías que se pueden visualizar son la B, C y E cada una con su identificador. Este algoritmo se descartó debido a que en los límites de decisión para la categoría B, las observaciones se mezclan con la categoría C, por lo tanto, al realizar una predicción para la selección de una categoría de horario con características de tipo C se obtendría en el 80% de los casos una predicción de tipo B.
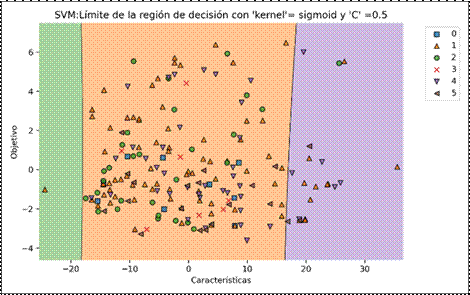
Figura 6. Resultado del algoritmo Máquina de soporte vectorial para predecir el horario de asignación de cita
Naive Bayes
Los resultados obtenidos en estas pruebas entregan una precisión del algoritmo igual a 21,27% y una validación cruzada de 33% con una desviación estándar de 0.11, como se muestra en el cuadro VI, lo que deja a este algoritmo como el menos preciso de todos. Tabla 6 muestra un resumen de los datos originales obtenidos.
Tabla 6. Resultados algoritmo: Naive Bayes
|
Métrica de validación |
Valor |
Desviación |
|
Score |
0.2127 |
|
|
cross_val_score |
0.33 |
[+-0]. 11 |
Fuente: los autores
Al igual que en las pruebas anteriores se realizó el reporte de clasificación donde se muestran diferentes métricas para la predicción del algoritmo. En este caso solo se obtuvieron precisiones mayores a cero para las categorías B y F, con 11 y 5 pruebas respectivamente.
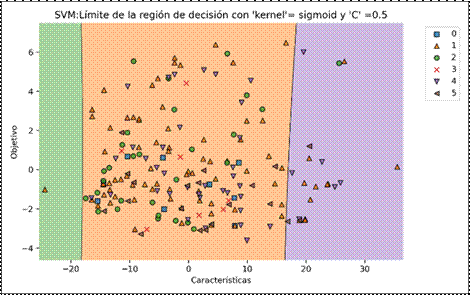
Figura 7. Resultado del algoritmo Naive Bayes para predecir el horario de asignación de cita
En la Figura 7 se puede ver el límite de región de decisión que se obtuvo del algoritmo, donde claramente se puede ver que la región con mayor área es la categoría B correspondiente a la figura 1 (triángulo) y en la parte inferior se visualiza la categoría F que tiene solo unos pocos registros.
4.2. Elección del mejor algoritmo
El algoritmo seleccionado para la implementación en el sistema es K-vecinos más cercano, esto se debe a que fue el único algoritmo que logró predecir más de 2 clases o categorías al momento de realizar las pruebas y para efecto de las pruebas fue el algoritmo con la mayor precisión.
Además, desde las gráficas de decisión fue el único algoritmo que logró agrupar de mejor manera las observaciones en cuanto a la variable de salida o clase categórica, en comparación con el algoritmo de árbol de decisión que para el total de los casos solo se clasificaba para una sola salida (categoría B) por lo que en el momento de realizar las predicciones aún con diferentes parámetros siempre se obtuvo como salida la categoría B. Cabe destacar que los datos que se lograron obtener están sesgados por lo que la salida de los algoritmos no es la más acertada y su implementación es cuestionable más tratándose de sistemas de salud.
CONCLUSIONES
Esta investigación propuso un sistema de gestión de reserva de citas con algoritmos de aprendizaje automático, capaz de predecir la hora ideal para una o varias personas según ciertos atributos que fueron utilizados para entrenar al algoritmo implementado.
Durante el proceso de análisis de los datos fue necesario realizar diversos procesos para obtener un conjunto de datos depurado y completo y así realizar las pruebas requeridas para cada algoritmo. En este análisis se evidenció que gran parte de las personas que respondieron la encuesta, siempre prefieren una cita médica durante la mañana, esto se debe a que en su mayoría las personas trabajan tiempo completo, tienen hijos dependientes de los padres o tutores, o que de alguna manera siempre es preferible invertir tiempo en las citas médicas durante la mañana que en la tarde.
La propuesta de un algoritmo que permita la asignación de citas médicas de acuerdo con el perfil del paciente debe ser estudiada con mayor profundidad ya que la precisión obtenida está por debajo de los valores esperados. Es por esta razón que para poder realizar la implementación en un sistema es necesario revisar los datos de origen con los cuales se entrenó el algoritmo y evitar los sesgos en los datos adquiridos, esto con el fin de mejorar la precisión y asignación en los sistemas APS.
Es importante señalar que la investigación entrega las bases para futuras investigaciones para el desarrollo de sistemas inteligentes centrados en mejorar la calidad de vida de las personas y especialmente de los más necesitados, mejorando el sistema de gestión de citas médicas en recintos de salud primario, donde el colapso en la atención y movimiento médico es un tema que se discute abiertamente y que puede sentar las bases para una mejora sustancial en cuanto a tiempo y recursos invertidos.
Agradecimientos
El equipo de trabajo agradece a la Universidad Católica del Norte a través del Fondo Investigación en Docencia versión 2021, por el financiamiento de esta investigación.
Declaration of Conflicting Interests
Los autores declaran que no existe ningún conflicto de interés potencial dentro de esta investigación, autoría y/o publicación de este artículo.
REFERENCIAS
Abdalkareem, Z. A., Amir, A., Al-Betar, M. A., Ekhan, P., & Hammouri, A. (2021). Healthcare scheduling in optimization context: A review. Health and Technology, 11(3), 445-469. From https://doi.org/10.1007/s12553-021-00547-5
Ahluwalia, S. C., Damberg, C. L., Silverman, M., Motala, A., & Shekelle, P. G. (2017). What Defines a High-Performing Health Care Delivery System: A Systematic Review. Joint Commission Journal on Quality and Patient Safety, 43(9), 450-459. From https://doi.org/10.1016/j.jcjq.2017.03.010
Almeida, P. F. (2018). Integração de rede e coordenação do cuidado: o caso do sistema de saúde do Chile. Ciência & Saúde Coletiva, 23, 2213-2228. From https://doi.org/10.1590/1413-81232018237.09622018
Annick, A. (2002). El sistema de salud chileno: 20 años de reformas. Salud Pública de México, 44(1), 60-68. From https://www.medigraphic.com/pdfs/salpubmex/sal-2002/sal021i.pdf
Ansell, C. y. (2018). Gobernando la turbulencia: una agenda organizacional-institucional. Perspectivas sobre la gestión pública y la gobernabilidad , 1 (1), 43-57. From https://doi.org/10.1093/ppmgov/gvx013
Arora, A., Bansal, S., Kandpal, C., Aswani, R., & Dwivedi. (2019). Measuring social media influencer index- insights from facebook, Twitter and Instagram. Journal of Retailing and Consumer Services, 49, 86-101. From https://doi.org/10.1016/j.jretconser.2019.03.012
Bass del Campo, G. C. (2012). Modelo de salud familiar en Chile y mayor resolutividad de la atención primaria de salud:?` contradictorios o complementarios? Repositorio Académico Universidad de Chile. From https://repositorio.uchile.cl/handle/2250/138083
Batun, S., & Begen, M. A. (2013). Optimization in Healthcare Delivery Modeling: Methods and Applications. En B. T. Denton (Ed.), Handbook of Healthcare Operations Management. Methods and Applications (pp. 75-119). Springer. From https://doi.org/10.1007/978-1-4614-5885-2_4
Bedregal, P., Zavala, C., Atria, J., Núñez, G., Pinto, M. J., & Valdéz, S. (2009). Acceso a redes sociales y de salud de población en extrema pobreza. Revista médica de Chile, 137(6), 753-758. From http://dx.doi.org/10.4067/S0034-98872009000600004
Bloom, D., Khoury, A., & Subbaraman, R. (2018). The promise and peril of universal health care. Science (New York, N.y.), 361(6404), eaat9644. Science, 361(6404), eaat9644. https://doi.org/10.1126/science.aat9644
Brandenburg, L., Gabow, P., Steele, G., Toussaint, J., & Tyson, B. (2015). Innovation and Best Practices in Health Care Scheduling. NAM Perspectives. doi:https://doi.org/10.31478/201502g
Coloma, F., Díaz, C., Espinoza, C., Flores, F., Guelfand, S., Leyton, C., . . . Mora, M. (2020). Análisis descriptivo de interconsultas emitidas en un período de 5 meses en dos centros de salud de la comuna de La Granja. From http://hdl.handle.net/11447/3351
Curtis, S. L.-R. (2018). Strengthening and implementing health technology assessment and the decision-making process in the Region of the Americas. Revista Panamericana de Salud Pública, 41, e165. From https://doi.org/10.26633/RPSP.2017.165
Dixit, S. K., & Sambasivan, M. (2018). A review of the Australian healthcare system: A policy perspective. SAGE Open Medicine, 6, 2050312118769211. https://doi.org/10.1177/2050312118769211
Dois, A., Contreras, A., Bravo, P., Mora, I., Soto, G., & Solís, C. (2016). Principios orientadores del Modelo Integral de Salud Familiar y Comunitario desde la perspectiva de los usuarios. Revista médica de Chile, 144(5), 585-592. From https://doi.org/10.4067/S0034-98872016000500005
Durrani, H. (2016). Healthcare and healthcare systems: Inspiring progress and future prospects. mHealth, 2, 3. https://doi.org/10.3978/j.issn.2306-9740.2016.01.03
Dzyabura, D., Jagabathula, S., & Muller, E. (2019). Accounting for discrepancies between online and offline product evaluations. Marketing. Science, 38(1), 88-106. https://doi.org/10.1287/mksc.2018.1124
Jahromi, A. T., Stakhovych, S., & Ewing, M. (2014). Managing B2B customer churn, retention and profitability. Industrial Marketing. Management, 43(7), 1258-1268. From https://doi.org/10.1016/j.indmarman.2014.06.016
Jiménez, S. B. (2018). Inequidad en el acceso a salud en Chile: Estudio multifactorial basado en la Encuesta CASEN del año 2013. Revista Chilena de Salud Pública, 22(1), 31-40. https://doi.org/10.5354/0719-5281.2018.51018
Kempa-Liehr, A. W., Lin, C. Y., Britten, R., Armstrong, D., Wallace, J., Mordaunt, D., & ’Sullivan, M. (2020). Healthcare pathway discovery and probabilistic machine learning. International Journal of Medical Informatics, 137, 104087. https://doi.org/10.1016/j.ijmedinf.2020.104087
Kim, H. (2021). Do online searches influence sales or merely predict them? The case of motion pictures. European Journal of Marketing, 55(2), 337-362. https://doi.org/10.1108/EJM-08-2019-0655
Pesse-Sorensen, K., Fuentes-García, A., & Ilabaca, J. (2019). Estructura y funciones de la Atención Primaria de Salud según el Primary Care Assessment Tool para prestadores en la comuna de Conchalí-Santiago de Chile. Revista médica de Chile, 147(3), 305-313. http://dx.doi.org/10.4067/S0034-98872019000300305
Pianykh, O. S., Guitron, S., Parke, D., Zhang, C., Pandharipande, P., Brink, J., & Rosenthal, D. (2020). Improving healthcare operations management with machine learning. Nature Machine Intelligence, 2(5), 266-273.https://doi.org/10.1038/s42256-020-0176-3
Rais, A., & Viana, A. (2011). Operations Research in Healthcare: A survey. International Transactions in Operational Research, 18(1), 1-31. https://doi.org/10.1111/j.1475-3995.2010.00767.x
Reynaldos-Grandón, K. S.-A.-M. (2018). Competencias profesionales, gestión clínica y grupos relacionados de diagnósticos. El caso de hospitales públicos chilenos. Revista de Salud Pública, 20, 472-478. From https://doi.org/10.15446/rsap.V20n4.66564
Salazar-Fernández, C. N. (2020). Autopercepción de salud en adultos mayores: moderación por género de la situación financiera, el apoyo social de amigos y la edad. Revista médica de Chile, 148(2), 196-203., 196-203. http://dx.doi.org/10.4067/s0034-98872020000200196
Salminen, J., Yoganathan, V., Corporan, J., Jansen, B. J., & Jung, S. (2019). Machine learning approach to auto-tagging online content for content marketing efficiency: A comparative analysis between methods and content type. Journal of Business Research, 101, 203-217. From https://doi.org/10.1016/j.jbusres.2019.04.018
Samorani, M. H. (2022). Overbooked and overlooked: machine learning and racial bias in medical appointment scheduling. Manufacturing & Service Operations Management, 24(6), 2825-2842. https://doi.org/10.1287/msom.2021.0999
Sánchez-Franco, M. J., Navarro-García, A., & Rondán-Cataluña, F. J. (2019). A naive Bayes strategy for classifying customer satisfaction: A study based on online reviews of hospitality services. Journal of Business Research, 101, 499-506. https://doi.org/10.1016/j.jbusres.2018.12.051
Schütte, S., Acevedo, P. N., & Flahault, A. (2018). Health systems around the world – a comparison of existing health system rankings. J Glob Health, 8(1), 010407. https://doi.org/10.7189/jogh.08.010407
Srinivas, S., & Ravindran, A. R. (2018). Optimizing outpatient appointment system using machine learning algorithms and scheduling rules: A prescriptive analytics framework. Expert Systems with Applications, 102, 245-261. https://doi.org/10.1016/j.eswa.2018.02.022
Syam, N., & Sharma, A. (2018). Waiting for a sales renaissance in the fourth industrial revolution: Machine learning and arti fi cial intelligence in sales research and practice. Industrial Marketing Management, 69, 135-146. https://doi.org/10.1016/j.indmarman.2017.12.019